확률이 어렵다고 느껴지지만 머신러닝을 위해 수학을 굳이 파고들 필요는 없다. 다만 개념을 아는 것은 중요할 것란 생각이다. 정규분포는 머신러닝에서 데이터의 집중도를 확인할 수 있고, 정규분포를 구할 수 있다는 것은 평균과 표준편차 확률 를 알 수 있다.

정규분포 Normal Distribution
정규분포 곡선은 아래와 같다.
정규분포 그래프의 가운데는 평균이며, 좌측, 우측으로 빼고 더한 값은 표준편차이다.
정확한 공식이나 계산은 모르더라도 아래의 이미지는 익혀두도록 하자.


머신러닝을 위한 정규분포
아주 많은 특정 데이터들이 빅데이터들이 많이 있을 때 데이터들은 여기저기 분포해 있고 나열되어 있다.
그럼에도 규칙이 있다.
어떤 값들이 개별적으로 존재하겠지만 대부분 비슷한 값들이 분포될 수 있다.
위의 이미지처럼 평균에 가까운 값들이 존재한다는 의미이고, 평균에서 멀어지는 값들이 존재한다는 것을 알 수 있다.
수학적으로 평균이나 확률을 알 수도 있지만 그래프를 이용하여 평균에 가깝고 먼 정도를 파악할 수 있는 것이다.
머신러닝에서 평균은 중요한 대목이 여기에 있기도 하다.
평균에서 가까울 수록 데이터의 정확도는 높아질 수 있다는 것이다.
정규분포 코드샘플
데이터수를 많이 만들어 정규분포 그래프를 표현해 보자.
정규분포는 영어로 Normal Distribution 이다.
정규분포를 구하기 위해 데이터를 만드는 것은 NumPy.random.normal() 함수를 사용한다.
함수의 파라미터는 NumPy.random.normal( 평균, 표준편차, 갯수 ) 이다.
그래프를 그리기 위해 Matplotlib.hist() 함수를 사용하여 히스토그램을 표현하기로 한다.
import numpy
import matplotlib.pyplot as plt
vNd = numpy.random.normal(10, 50, 1000)
plt.hist(vNd)
plt.show()평균은 10이고, 표준편차가 50인 숫자 1000개를 만들고 정규분포 데이터를 만들었다.
위의 개요에서 언급한 것과 비슷한 정규분포도가 만들어 진 것을 볼 수 있다.

코드를 조금 수정하여 상세하게 보도록 해 보자.
hist() 함수에 그래프의 갯수 10개를 지정했다.
vNd = numpy.random.normal(10, 50, 1000)
print("정규분포 Normal Distribution : ", type(vNd), vNd)
plt.hist(vNd, 10)
plt.show()랜덤으로 나온 1000개의 많은 데이터들이 있지만
평균 0에 가까운 값들이 최대 200개이상이 있다는 것을 알 수 있다.

코드를 다시 수정해 보자
정규분포 데이터를 만듬에 있어 위의 코드에서 숫자의 위치만 바꿔주었다.
평균은 50이고, 표준편차는 10인 숫자 1000개를 만들어 보고 정규분포도를 확인해 본다.
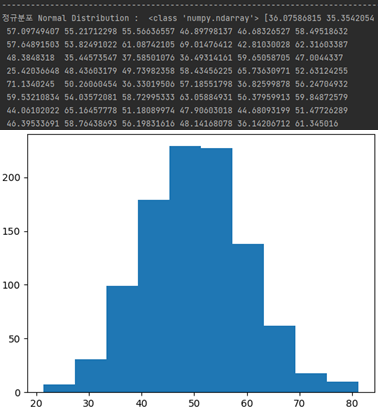
vNd = numpy.random.normal(50, 10, 1000)
print("정규분포 Normal Distribution : ", type(vNd), vNd)
plt.hist(vNd, 10)
plt.show()만들어진 1000개의 수 중 평균이 50에 가까운 수와 평균에서 가장 멀리 떨어진 수를 확인할 수 있다.
정규분포 설명
정규분포에 대한 자세하고 쉽게 나온 영상하나를 공유한다.
머신러닝을 위해 깊이 있게 수학을 공부할 필요는 없겠지만, 개념을 이해를 위한 공부는 필요하다.
당연하겠지만, 머신러닝을 위한 툴들은 거의 영문이기 때문에 용어 또한 익혀두는 것이 좋다.
'programming > AI' 카테고리의 다른 글
| 머신러닝 산점도 두 가지 이상 데이터의 상관관계를 점으로 표현 Machine Learning Scatter Plot (0) | 2021.08.14 |
|---|---|
| 구글 텐서플로우란 머신러닝 오픈소스 플랫폼 (0) | 2021.08.13 |
| 오렌지3 머신러닝 화면구성 살펴보기 메뉴 위젯 캔버스 영역 보기 (0) | 2021.08.12 |
| 머신러닝 오렌지3 시작하기 위젯의 사용 데이터테이블과 산점도 연결하기 Using File DataTable and Scatter Plot Widget in Orange3 (0) | 2021.08.11 |
| 오렌지3 머신러닝 툴 다운로드와 실행 하는 방법 (0) | 2021.08.10 |




댓글